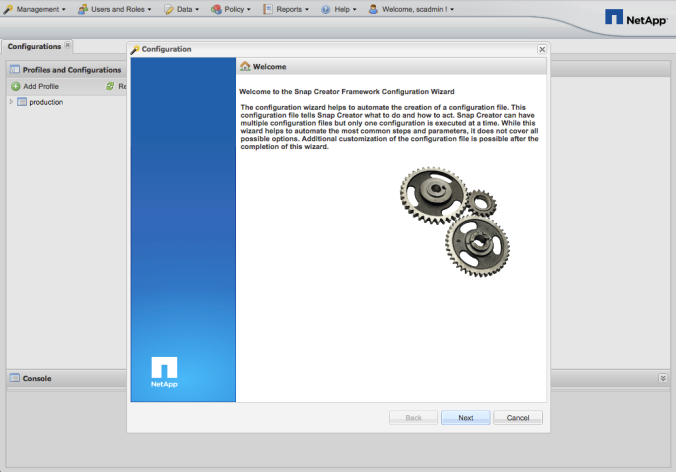
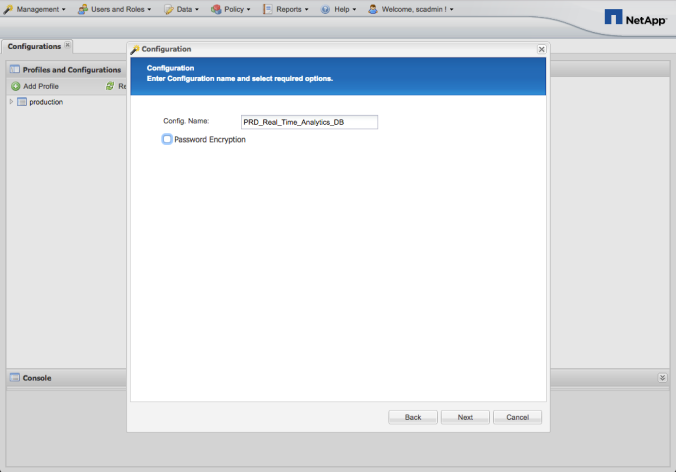
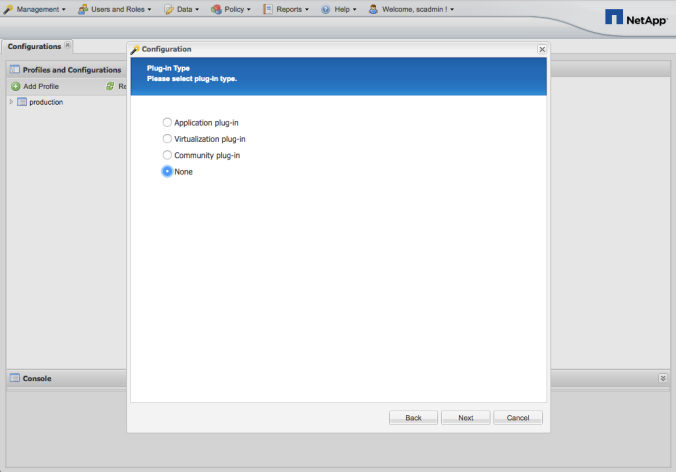
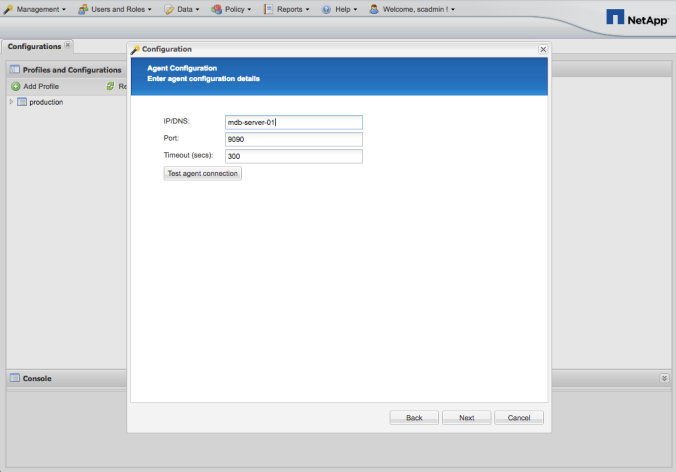
MongoDB World 2017 (MDBW17) was amazing. You know, it is a conference with a marketing vies, but there are conferences and conferences.
MongoDB has been innovating on the database market since it has been born, but they made crystal clear at MDBW17 that a new milestone was achieved.
I’m pretty sure that the features they released and the ones that they are about to release on MongoDB 3.6 will change the way we create and deploy applications.
Let’s see if I can summarize all the cool stuff on this post.
MongoDB Advocacy Summit
Being part of the MongoDB Advocacy community is an awesome thing. We have been always in touch with each other virtually, and some of them have already met in person, but this year was special for me. I have the opportunity to meet my Advocate buddies in person.
The day was divided in two parts:
- During the morning: roadmap overview presented by Eliot Horowitz(CTO and Co-founder), Dan Pasette (VP of Core Engineering), Sahir Azam (VP of Cloud Products and GTM), Michael Cahill (Director of MongoDB Storage Engines) and Asya Kamsky (Lead Product Manager)
- Afternoon: unconference format. Here is how it works. People attending the summit either suggests or vote on subjects that they would like to discuss. Then, the three most voted subjects are spread across the room and people can choose which subject they want to join on a discussion creating three discussion groups. Each group has a volunteer to take notes and at the end each group summarizes the takeaways of each subject.
It was a very productive day. I’ve learned a lot from other Advocates.
Francesca Krihely, Jay Destro and Meghan Gill made an outstanding work putting the Advocate community together on Monday. Thanks guys! It was amazing.

Left to right: Logwriter, Jay Destro and Francesca Krihely
A New World of Possibilities Unleashed by MongoDB
Are you ready? Tons of new features and services were announced during the Keynote session.
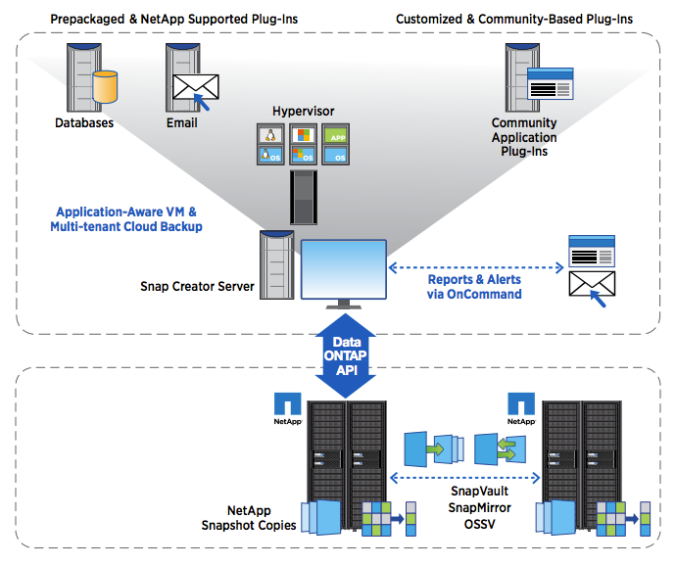
Two announcements were shining on stage: MongoDB Stitch and MongoDB Charts.
MongoDB Stitch is a Backend-as-a-Service offer that promises to let developers focus on building application instead of service integration and backend infrastructure.
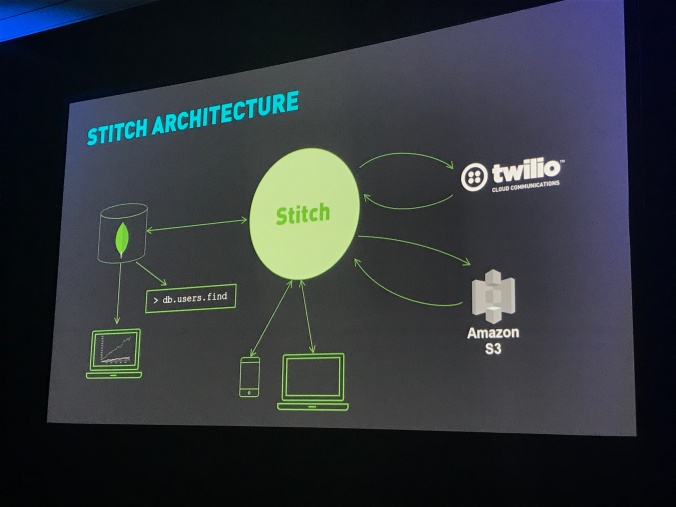
MongoDB Stitch Architecture Diagram
Described by Eliot Horowitz as a REST API for MongoDB and a service composition tool anywhere you want.
Definitely a candidate for a future post as soon as I learn it in more depth.
MongoDB Charts is a BI tool, which connects on ATLAS and allows you to explore and visualize your data using charts. My understanding was that is only available for ATLAS, but I have to double check that.
MongoDB Charts Dashboard
MongoDB ATLAS has completed one year since it was launched at MDBW16 and it’s been a successful DBaaS solution.
MongoDB 3.6 will bring interesting improvements such as retryable writes, notification API, better array manipulation, improvements in the aggregation framework and schema validation using a JSON.
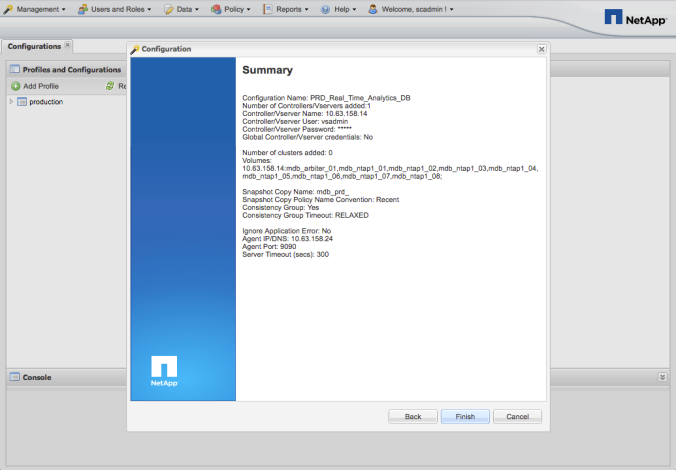
NetApp Booth
NetApp was a platinum sponsor for MDBW17. You might be question yourself: “What a data storage company like NetApp is doing at MDBW17?”.
The first thing it might come to your mind would be: “Databases have to persist data on disk. NetApp sells data storage systems. Bingo!”.
Well, NetApp isn’t only a data storage company. We’ve reinvented ourselves as a company and became a data management company. Our solutions are much more than data storage systems. Click here to get more information about NetApp or if you have any specific questions, leave comment on this post and I will get back to you.

NetApp Booth at MDBW17
Thanks for reading it and let me know if you have any questions.
See you next post!
Logwriter